Chapter 06
비지도 학습
.
지도학습을 끝내고 딥러닝에 본격적으로 들어가기 전
비지도 학습에 대해 알아보자
06-1 군집 알고리즘
비지도 학습은 지도학습과 다르게 타깃이 주어지지 않는다.
즉, 주어진 데이터를 통해 <비슷하다>라는 것을 추출해야 한다.
여기서는 사진을 종류별로 분류하려 한다.
.
우리가 눈으로 보고 분류하듯 픽셀을 이용해서 분류해보자.

100*100픽셀의 사과로 추정되는 사진이다.
한 픽셀은 0~255까지의 색상을 나타낼 수 있고 0에 가까울수록 검게 보인다.
(컴퓨터는 출력을 위해 계산을 하는데 이때 의미를 부여하기 위해 필요 없는 배경을 0에 가깝게 배정한다)
.
이 픽셀정보는 위에서부터 한 행씩 읽힌다.
즉, 100*100의 2차원 배열이 10,000자리의 1차원 배열이 된다.
그리고 우리는 사과, 파인애플, 바나나를 각 100개씩 분류할 예정이다.
.
각 셀(픽셀 하나하나)들을 평균내서 분류하고자 한다.
데이터를 나열해서 (100, 10,000)의 배열 형태로 보면
행별로 하나하나 평균내면 된다.

300개의 파일에 대해 히스토그램으로 표현하면 위와 같이 나타난다.
위치별 픽셀 평균값들이 어느 구간에서 어떤 빈도로 나타나는지 확인할 수 있다.
쉽게 말해 명도로 분류한 것이다.
.
이렇게 되면 사진에서 차지하는 영역의 크기에 따라, 형태에 따라 분류하기 어려울 수 있다.
그러면 이번에는 셀이 아닌 각 픽셀의 평균을 계산해 보자.
이렇게 하면 형태별로, 채도별로 구분할 수 있지만
그래도 뭔가 꺼림찍하다.
하지만 사진 전체 영역에서 물체가 차지하는 부분의 크기 비율이 비슷하다면 맞지 않을까?
실제로, 이렇게 구한 평균값으로 300개의 과일에서 오차가 가장 적은 100개를 구하면 다음과 같이 나온다.
apple_mean으로 구했을 때 100개 모두 사과가 나왔다.
이렇게 비슷한 샘플끼리 그룹으로 모으는 작업을 군집이라고 한다.
군집 알고리즘을 통해 만든 그룹은 클러스터라고 부른다.
.
지금 한 것은 우리가 데이터에 어떤 종류의 과일이 있는지 아는 상태였다.
덕분에 사진 평귱값도 구해서 가장 가까운 과일을 찾을 수 있었다.
하지만 실제 비지도 학습에서는 타깃값을 모르기에 평균값을 미리 구할 수 없다!
06-2 k-평균
k-평균 군집 알고리즘은 데이터에서 평균값을 자동으로 찾아준다.
그 원리는 다음과 같다.
.
전제: 평균값은 각 클러스터의 중심에 위치한다. (평균값의 정의)
1. 우선 무작위로 k 개의 클러스터 중심을 정한다.
2. 각 중심에 대해 k 개의 클러스터 샘플을 묶는다.
3. 이렇게 만든 샘플들의 평균값으로 중심을 다시 잡는다.
2번, 3번 반복
만약 클러스터 중심에 변화가 없다면 군집을 끝낸다.
.
해당 알고리즘은 이전 단원들과 동일하게 sklearn 모듈에서 구현 가능하다.
실제로 실행해보면 클러스터를 3개로 지정해도 각 100개로 채워지지는 않는다.
어디에는 90개 언저리로 군집되기도 한다.
각 데이터와 클러스터 중심 사이의 최소 거리로 예측하기 때문에 어느정도 오차가 있다.
.
하지만 실전에서는 클러스터 개수조차 모르기에 설정할 수 없다.
하지만 k-평균 알고리즘은 클러스터 개수를 사전에 지정해야 한다.
최적의 k 찾기
.
책에서는 대표적인 방법 중 하나인 엘보우 방법을 사용한다.
k-평균 알고리즘은 클러스터 중심과 각 샘플 사이의 거리를 잴 수 있다.
이 거리의 제곱 합을 이너셔라고 부른다.
이너셔는 클러스터에 속한 샘플이 얼마나 가깝게 모여 있는지를 나타낸다.
쉽게 말해 분산을 나타낸다고 생각하면 된다.
.
일반적으로 클러스터 개수가 늘어나면
클러스터 각각의 크기는 줄어들기 때문에 이너셔도 줄어든다.
이 변화를 관찰해 감소하는 속도가 꺾이는 지점을 찾으면 된다.
이 지점부터는 밀집된 정도가 크게 개선되지 않기 때문이다.
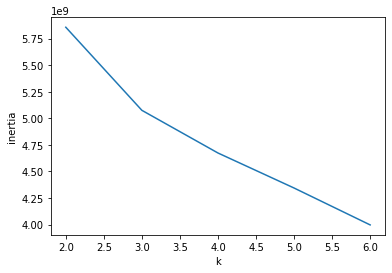
여기서는 그렇게까지 극적인 변화는 아니지만 3.0지점에서 기울기가 변하는 것을 알 수 있다.
.
이렇게 클러스터 중심까지 거리도 특성으로 사용하면 손쉽게 정확도를 높일 수 있기에
훈련 데이터의 차원을 크게 줄일 수 있다.
데이터셋의 차원도 줄이면 알고리즘의 속도를 대폭 향상시킬 수 있지 않을까?
06-3 주성분 분석(PCA)
점점 데이터의 양도 많아지고 각각의 크기도 커진다.
저장공간의 부족도 그렇고 알고리즘의 속도도 느려진다.
차원을 축소시켜 문제를 해결하자.
.
주성분 분석은 대표적인 차원 축소 알고리즘이다.
가장 잘 나타내는 일부 특성(주성분)만 남겨 데이터 크기를 줄이고 모델의 성능을 향상시킨다.
또한, 손실은 최대한 줄이면서 복원할 수도 있다.
.
주성분은 분산이 가장 큰 방향을 따른다.
3차원이라면 데이터가 타원형태로 분포하기 때문에 타원의 긴 주축을 주성분으로 삼는다.
첫 번째 주성분을 찾은 다음 이 벡터에 수직이고 분산이 다음으로 큰 방향을 찾는다.
따라서 n차원에 대해 최대 n개의 주성분으로 데이터를 특정할 수 있다.
이렇게 데이터의 군더더기를 제외한 주성분만 이용할 수 있다.
10,000개의 픽셀(특성)을 가진 데이터를 50개의 주성분(특성)으로 압축시킬 수 있다.
만약 주성분을 최대로 사용한다면 완벽하게 원본 데이터를 재구성할 수 있을 것이다.
.
각 주성분이 원본 데이터의 분산을 얼마나 잘 나타내는지 기록한 값을 설명된 분산이라고 한다.
설명된 분산의 비율을 그래프로 그리면 카이제곱분포와 비슷한 형태가 나온다.

즉, 초기 몇 개의 주성분이 데이터의 거의 모든 것을 담고 있다는 뜻이다.
무작정 데이터를 PCA로 압축시켜 사용할 수는 없기에
원본 데이터와 축소한 데이터를 모델에 적용해 얼마나 차이나는지 평가해보자.
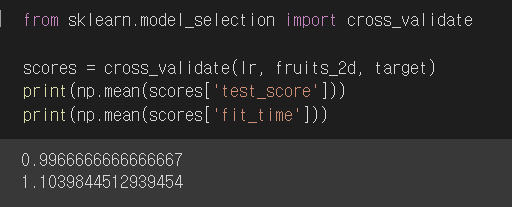
3개의 과일 사진을 분류해야 하므로 간단히 로지스틱 회귀 모델을 사용한다.
 |
 |
교차검증을 시행했을 때 원본 데이터는 특성이 10,000개나 되기 때문에 금방 과대적합되었다.
PCA의 경우 정확도가 100%나 나왔고 훈련 시간도 0.02초로 1.1초인 원본에 비하면 어마어마한 감축이다.
.
앞서 PCA의 주성분의 개수를 지정했는데
설명된 분산의 비율을 지정하면 그 비율에 도달할 때까지 주성분을 자동으로 찾을 수 있다.
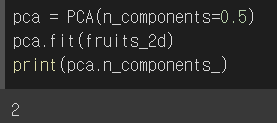
설명된 분산을 50%로 지정했을 때 해당 비율까지의 주성분의 수는 2개이다.
단 2개의 특성만으로 원본 데이터 분산의 50%를 표현할 수 있다!
이 데이터로 교차검증을 수행하면 99%의 정확도에 런타임 0.05초가 나온다.
2개의 특성만으로도 정확도가 99%이다.
하지만 실제 클러스터를 확인해보면 여전히 사과와 파인애플이 혼돈돼 섞여있다.
.
주성분 즉, 특성이 2개라면 2차원 데이터이므로
2차원 좌표축 평면 상에 산점도를 구할 수 있다.

가로축과 세로축은 각각 첫번째 주성분과 두번째 주성분을 나타낸다.
각 값이 어떻게 생긴건지는 PCA알고리즘을 뜯어봐야 알 수 있을 것 같다.
산점도를 보면 알 수 있듯 사과와 파인애플의 맞닿아 있기 때문에
클러스터 중심에 대한 거리에서 어느정도 오차가 생긴 것 같다.
이렇게 차원 축소하면 저장공간 확보는 물론, 모델 러닝타임도 월등히 줄일 수 있지만
차원을 대폭 줄임으로써 시각화에 용이해 한눈에 알아보기 편하다.
6장에서는 비지도 학습에 대해 간략히 알아보았다.
사진을 분류하기 위해 픽셀값을 이용했고
타깃값이 없기에 k-평균 알고리즘을 사용해 자동으로 군집화했다.
데이터가 많아져 저장공간을 많이 차지하고 알고리즘 속도도 느려지기에
대표적인 차원 축소 방법인 PCA(주성분 분석)를 이용해
특성의 수를 줄여 월등한 성과를 내었다.
'Programming > 혼공머신 8기.py' 카테고리의 다른 글
| 추가 학습(1)_합성곱 신경망 (0) | 2022.08.16 |
|---|---|
| 혼자 공부하는 머신러닝 + 딥러닝 [6주차]_fin (1) | 2022.08.15 |
| 혼자 공부하는 머신러닝 + 딥러닝 [4주차] (0) | 2022.07.27 |
| 혼자 공부하는 머신러닝 + 딥러닝 [3주차] (0) | 2022.07.18 |
| 혼자 공부하는 머신러닝 + 딥러닝 [2주차] (0) | 2022.07.13 |