Chapter 05
트리 알고리즘
.
자료구조나 알고리즘을 공부해 보면 트리 형태나 노드 형태를 보게 되는데
뭔가 이해하기 쉬우면서도 어려운 구조다
이 책에서는 그래도 쌩으로 구현하는 게 아니라
있는 모델을 잘 활용해서 결과를 내는 느낌이라 학습에는 큰 어려움이 없을 것 같다.
05-1 결정 트리
다루는 데이터의 크기가 몇 천개로 늘었다..
이전에 공부하는 로지스틱 회귀 모델은 데이터를 직접 학습해
계수와 가중치를 알맞게 조절해 함수를 만들었다.
하지만 특성이 많아질수록 모델을 설명하기 어렵다.

반면 결정 트리 모델은 이유를 설명하기 쉽다.
스무고개처럼 계속 예/아니요 질문으로 분류하며 정답을 맞춰나간다.

위 그림을 보면 각 노드가 어떤 특성으로 나뉘는지 이해하기 쉽다.
테스트 조건에 따라 총 샘플들이 왼쪽, 오른쪽 노드로 나뉘게 된다.
여기서 gini는 <지니 불순도>를 의미하며 샘플을 나누는 기준이 된다.
지니 불순도 = 1 - (음성 클래스 비율2 + 양성 클래스 비율2)
결정 트리 모델은 부모 노드와 자식 노드의 불순도 차이가 가능한 크도록 트리를 성장시킨다.
불순도는 지니 불순도처럼 제곱이 아니라 밑이 2인 로그를 사용하여 곱하는 엔트로피 불순도도 있다.

트리는 무작정 끝까지 자라나 과대적합이 되기 쉽상이다.
따라서 자라날 수 있는 최대 깊이를 지정해 원하는 지점에서 분류를 멈출 수 있다.
.
또한, 불순도는 클래스별 비율을 가지고 계산하므로
특성값의 스케일은 모델에 아무런 영향을 미치지 않는다.
따라서 표준화 전처리를 할 필요가 없다는 장점이 있다.
.
그리고 결정 트리는 어떤 특성이 가장 유용한지 나타내는 특성 중요도를 계산해 준다.
따라서 결정 트리 모델을 특성 선택에 활용할 수 있다.
05-2 교차 검증과 그리드 서치
이제 원하는 모델을 얻기 위해 최대 깊이를 얼마로 지정해야 하는지만 남았다.
결국 모델을 많이 만들어 평가해야 하는데 테스트 세트에 맞는 모델이 되지 않도록
훈련 세트 : 검증 세트 : 테스트 세트 = 6 : 2 : 2 비율로 검증세트를 만들어 평가하고
마지막에 테스트 세트로 최종 점수로 평가한다.
검증 세트를 만드느라 훈련 세트가 줄었기에 교차 검증을 이용해
안정적인 검증 점수를 얻고 훈련에 더 많은 데이터를 사용하고자 한다.
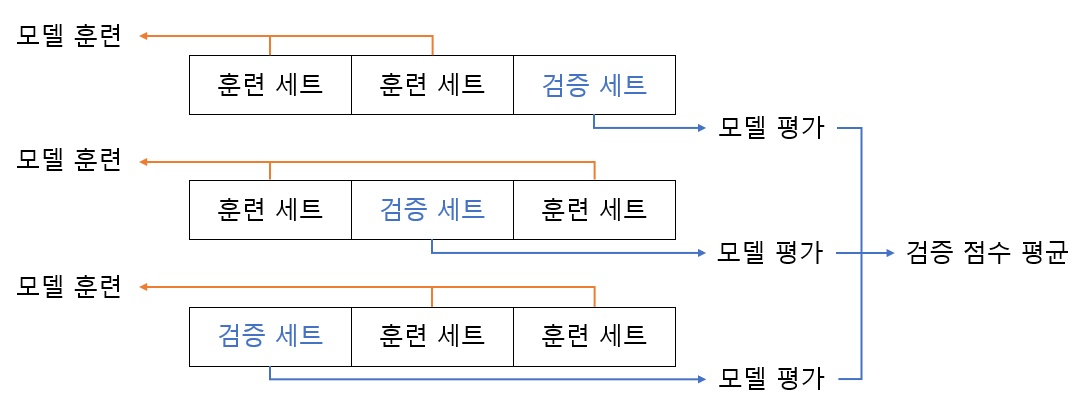
교차 검증은 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복한다.
훈련 세트를 몇(k) 부분으로 나누냐에 따라 k-폴드 교차 검증이라 부른다.
보통 5-폴드나 10-폴드를 많이 사용한다
각 폴드에서 계산한 검증 점수를 평균하기 때문에 안정된 점수로 생각할 수 있으며
교차 검증을 수행하면 해당 모델에서 얻을 수 있는 최상의 검증 점수를 가늠해 볼 수 있다.
최대 깊이를 제한하는 max_depth는 사용자가 지정해야 하는 하이퍼 파라미터다.
하지만 매개변수는 이것만 있는게 아니며 서로 독립적이지 않고 일부 종속된 것도 있어서
하나 하나 개별적으로 최적의 값을 찾기 어렵다.
for 문을 사용하면 직접 구현할 수 있지만 여기서는 사이킷런에서 제공하는 그리드 서치를 사용한다.
GriidSearchCV 클래스는 하이퍼파라미터 탐색과 교차 검증을 한 번에 수행한다.
심지어 클래스의 n_jobs 매개변수에서 병렬 실행에 사용할 CPU 코어 수를 지정할 수 있다.
.
책에서는 노드를 분할하기 위한 불순도 감소 최소량인 min_impurity_decrease,
노드를 나누기 위한 최소 샘플 수인 min_samples_split,
그리고 트리의 깊이인 max_depth 매개변수를
각각의 범위로 제한해 교차 검증을 진행했다.
이 매개변수의 모든 경우를 수행하기에 몇 천개의 모델이 생성되고
최상의 조합을 찾을 수 있다.
매개변수의 값이 수치일 때 값의 범위나 간격을 미리 정하기 어려울 수 있다.
또 너무 많은 매개변수 조건이 있어 그리드 서치 수행 시간이 오래 걸릴 수 있다.
이럴 때 랜덤 서치를 사용하면 좋다.
.
랜덤 서치는 값의 목록이 아닌 샘플링할 수 있는 확률 분포 객체를 전달한다.
즉, 일정한 범위에서 각 값이 모두 같은 확률로 고르게 뽑히는 균등 분포에서 샘플링한다.
쉽게 말해, 수치형이고 특히 연속적인 실수값에 대해
뽑힐 확률이 모두 같은 랜덤 시행을 한다는 것이다.
.
지정된 횟수로 샘플링하므로 그리드 서치에 비해
교차 검증 수를 줄이면서 넓은 영역을 효과적으로 탐색할 수 있다.
따라서 시스템 자원이 허락하는 만큼 탐색량을 조절할 수 있다.
05-3 트리의 앙상블
데이터베이스나 엑셀로 표현하기 좋은 정형 데이터를 다루는 데
가장 뛰어난 성과를 내는 알고리즘은 앙상블 학습이라고 한다.
비정형 데이터는 규칙성을 찾기 어려워 신경망 알고리즘을 사용해야 한다.
앙상블 학습의 대표 주자 중 하나인 랜덤 포레스트는 결정트리를 랜덤하게 만들어
숲을 만들고 각 결정 트리의 예측을 사용해 최종 예측을 만든다.
.
먼저 훈련 세트의 크기와 같게 복원 추출(중복 허용)하여 부트스트랩 샘플을 만들어
각각 결정 트리 훈련을 진행한다.
부트스트랩 샘플에 포함되지 않고 남는 OOB 샘플로는 검증 세트의 역할을 대신할 수 있다.
여기서 각 노드를 분할할 때 전체 특성 중에서 일부 특성을 무작위로 고른 후
이 중에서 최선의 분할을 찾는다.
분류 모델의 경우 전체 특성 개수의 제곱근만큼의 특성을 선택하고 회귀 모델의 경우 전체 특성을 사용한다.
분류일 때는 각 트리의 클래스별 확률을 평균하여 가장 높은 확률을 가진 클래스를 예측으로 삼고
회귀일 때는 단순히 각 트리의 예측을 평균한다.
.
랜덤 포레스트는 랜덤하게 선택한 샘플과 특성을 사용하기 때문에
과대적합되는 것을 막아주고 안정적인 성능을 얻을 수 있다.
즉, 하나의 특성에 과도하게 집중되지 않고 일반화 성능을 높이게 된다.
랜덤 포레스트와 매우 비슷한 엑스트라 트리라는 것도 있다.
차이점은 엑스트라 트리는 부트스트랩 샘플을 사용하지 않는다.
즉각 결정 트리를 만들 때 전체 훈련 세트를 사용하며 노드를 분할할 때 무작위로 분할한다.
무작위성이 크기 때문에 더 많은 결정 트리를 훈련해야 한다.
하지만 랜덤하게 노드를 분할하기 때문에 계산 속도가 빠르다는 장점이 있다.
그레디언트 부스팅이라는 것도 있다.
깊이가 얕은 결정 트리를 사용하여 이전 트리의 오차를 보완하는 방식으로 앙상블 한다.
4장의 경사 하강법과 굉장히 유사하다.
.
분류에서는 로지스틱 손실 함수를 사용하고 회귀에서는 평균 제곱 오차 함수를 사용해서
결정 트리를 계속 추가하지만 깊이가 얕은 트리를 사용해 적합한 모델로 나아간다.
매개변수를 이용해 전체 훈련 세트나 세트의 일부를 사용할 수 있다.
확률적 경사 하강법이나 미니배치 경사 하강법과 유사하게 생각하면 된다.
.
성능이 뛰어나지만 병렬로 훈련할 수 없어 속도가 조금 느리다.
학습률 매개변수로 모델의 복잡도를 제어할 수 있지만
너무 크면 과대적합된 모델을 얻을 수 있다.
그레디언트 부스팅의 속도와 성능을 더욱 개선한 것은
정형 데이터를 다루는 머신러닝 알고리즘 중에 가장 인기가 높은
히스토그램 기반 그레디언트 부스팅이다.
.
특성을 256개의 구간으로 나누어 노드를 분할할 때
분할 속도가 매우 빨라 최적의 분할을 빠르게 찾을 수 있다.
5장까지 해서 드디어 지도 학습에 대한 커리를 끝냈다.
이제 6장 비지도 학습만 하면 머신러닝 파트는 끝난다!!

'Programming > 혼공머신 8기.py' 카테고리의 다른 글
| 혼자 공부하는 머신러닝 + 딥러닝 [6주차]_fin (0) | 2022.08.15 |
|---|---|
| 혼자 공부하는 머신러닝 + 딥러닝 [5주차] (0) | 2022.08.10 |
| 혼자 공부하는 머신러닝 + 딥러닝 [3주차] (0) | 2022.07.18 |
| 혼자 공부하는 머신러닝 + 딥러닝 [2주차] (0) | 2022.07.13 |
| 혼자 공부하는 머신러닝 + 딥러닝 [1주차] (0) | 2022.07.07 |