어쩌다가 SNS에서 혼공학습단 8기를 모집한다는 글을 보게 됐고
마침 머신러닝, 딥러닝 쪽에 관심이 있었고
뭔가 내가 찍먹해보고 싶은 내용들이 담긴 책인 것 같아서
이렇게 하게 되었다ㅎㅎ

전체적으로 크게 어렵지 않고 어느정도 관심 있는 사람들에게는
정말 '찍먹'하기 좋은 난이도의 책이다.
쓰이는 알고리즘 같은 경우에도 책에 사례같은 내용으로
어떤 상황에 어떤 사고 흐름으로 코드를 전개하는 지 보여줘서
이해하기 쉽고 재밌게 공부할 수 있다.
(파이썬, 선형대수학, 기초통계학을 어느정도 다루고 공부했다면 어려움 없이 완독할 수 있을 겁니다.)
01-1 인공지능과 머신러닝, 딥러닝
책을 시작하기 앞서 인공지능, 머신러닝, 딥러닝이 무엇인지 소개하는 절이다.
인공지능: 사람처럼 학습하고 추론할 수 있는 지능을 가진 시스템을 만드는 기술
- <강인공지능>은 사람과 구분하기 어려운 지능을 가진 컴퓨터 시스템
- <약인공지능>은 특정 분야에서 사람의 일을 도와주는 보조 역할
머신러닝: 규칙을 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- 지도학습: 입력과 타깃을 전달하여 모델을 훈련한 다음 새로운 데이터를 예측하는 데 활용
- 비지도 학습: 타깃 데이터가 없기에 입력 데이터에서 어떤 특징을 찾는 데 주로 활용
딥러닝: 많은 머신러닝 알고리즘 중 인공 신경망을 기반으로 한 방법들을 통칭하여 부름
01-2 코랩과 주피터 노트북
다른 설치 프로그램 없이 웹 브라우저에서 파이썬 코드를 실행할 수 있는 방법에 대해 소개한다.
구글 코랩은 웹 브라우저에서 무료로 파이썬 프로그램을 테스트하고 저장할 수 있는 서비스이다.
구글 드라이브에 저장되며, 대화식 프로그래밍 환경인 주피터를 커스터마이징해서 가상 서버를 사용하기에 RAM과 디스크 사용량을 알 수 있다.
구글 클라우드의 컴퓨터 엔진에 연결되어 있어 약 12기가의 메모리와 100기가의 디스크 공간을 사용할 수 있다.
01-3 마켓과 머신러닝
여기서부터 본격적인 내용이 시작된다.
이 절은 가장 간단한 머신러닝 알고리즘 중 하나인
k-최근접 이웃을 사용하여 2개의 종류를 분류하는 머신러닝 모델을 훈련한다.
각 절마다 주인공이 어떠한 사건 때문에 알고리즘을 이용해 문제를 해결하게 되는 내용으로 코드를 설명한다.
그래서 생각없이 '그렇구나~'하고 따라가면 어느새 나도 모든 절차를 이해하게 된다..

시작은 간단하게 데이터를 리스트에 담고 matplotlib 패키지를 이용해 산점도를 그려본다.
여기서는 빙어와 도미의 길이와 무게 특성을 이용하는데 많은 양의 데이터를 파이써닉하게 다루는 게 볼만 하다.
예를 들어, 나열된 리스트에서 원소를 하나씩 꺼내주는 zip() 함수와 for 문을 이용해 2차원 리스트를 만들거나
fish_data = [[l, w] for l, w in zip(length, weight)]이진 분류이기에 꽤 귀찮은 작업을 다음과 같이 간단하게 만든다.
fish_target = [1] * 35 + [0] * 14
이렇게 데이터를 만들고, 사이킷런 패키지에서 k-최근접 이웃 알고리즘을 구현한 클래스를 임포트해서 사용한다.
클래스의 객체를 만든 후 data와 target을 전달해
먼저 fit() 메서드를 이용해 학습(훈련)시키고 score() 메서드를 이용해 모델을 평가한다.
0 ~ 1 사이의 값을 반환하며 1은 모든 데이터를 정확히 맞혔다는 것을 나타낸다.

n-neighbors 매개변수를 조절해 주위의 다른 데이터와 비교해 직선거리에 따라 다수를 차지하는 것을 정답으로 사용한다.
그래서 위와 같이 사용한 49개의 데이터 중 35개가 도미였기에 49개를 다 비교하면 35/49의 값이 정확도로 나오게 된다.

n-neighbors 매개변수를 적당히 조절하면 1에 가까운 정확도를 얻을 수 있다.
그래서 위와 같이 코드를 작성하면 최대 17개까지다른 데이터와 비교하면 정확도가 1이 나온다는 것을 알 수 있다.
훈련과 평가까지 마쳤으면 predict() 메서드를 이용해 새로운 데이터에 대해 알고리즘이 예측하게 할 수 있다.
02-1 훈련 세트와 테스트 세트
이전 절에 문제점이 있었다.
훈련에 사용한 데이터를 평가에서도 사용했으니 당연히 100% 다 맞춘다는 것!
성능을 제대로 평가하려면 훈련 데이터와 평가에 사용할 데이터가 각각 달라야 한다.
그리고 각 데이터는 샘플링 평향을 겪지 않도록 합리적인 비율로 개체들이 섞여 있어야 한다.
여기서부터는 편하게 파이썬의 대표적인 배열 라이브러리인 넘파이를 쓴다. (배열은 행렬과 비슷하다)
넘파이는 리스트를 배열로 바꾸는데에 활용하기 좋다.
여기서는 각 특성을 열로 나누어서 크기 (49, 2)의 배열을 만든다.
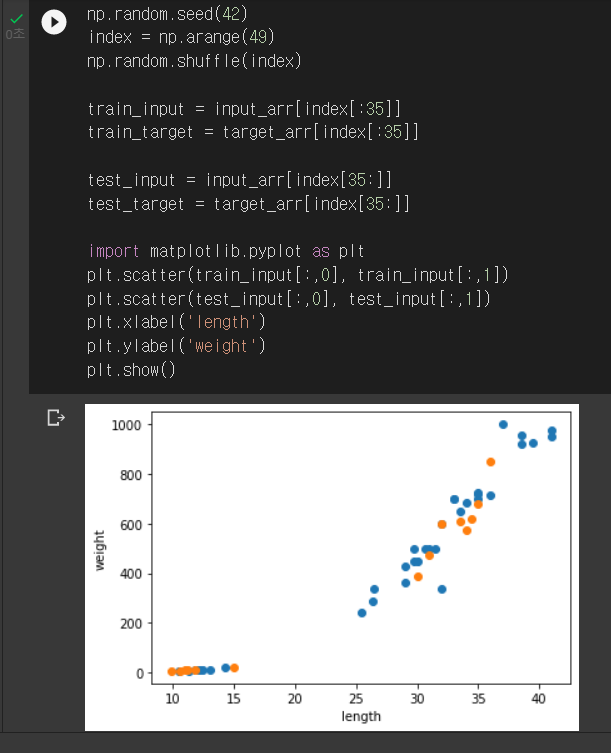
원본 데이터에 영향이 안 가게 index 리스트를 만들고 무작위로 섞었다.
(무작위 결과를 동일하게 유지하기 위해 seed를 사용함)
그리고 배열 인덱싱을 이용해 넘파이 배열을 인덱스로 전달해 훈련 세트와 테스트 세트를 만든다.
2차원 배열은 행과 열 인덱스를 콤마(,)로 나누어 지정한다. (train_input[:,0]은 1열(0번째) 전체를 의미한다)
이렇게 훈련 세트와 테스트 세트가 나뉜 것을 산점도를 통해 확인할 수 있다.
훈련 세트는 클수록 좋고 테스트 세트는 전체 데이터에서 20~30%를 테스트 세트로 사용하는 경우가 많다고 한다.
02-2 데이터 전처리
이렇게 세트를 나눠서 처리하면 다 될 줄 알았지만 또 문제점이 있었다.
x축과 y축의 특성 스케일이 달라서 수치적으로 계산하는 거리 기반 알고리즘은 산점도와 다른 결과를 출력하기도 한다!
이런 경우, 두 특성 스케일을 표준화해야 하는데 여기서는 표준점수를 이용해 변환했다.
고등학교 확률과 통계 시간에 배웠던 표준정규분포표를 만들 때 사용했던 표준화와 같다.
각 데이터에서 평균을 빼고, 표준편차로 나눠주는 과정이다.
이렇게하면 분포표의 평균은 0이 되고, 표준편차는 1이 된다.
이와중에 주인공은 데이터를 더 잘 다루게 되었다.
각 특성에 대한 크기 (49, 2)의 배열을 np.column_stack() 메서드로 간편하게 만들고
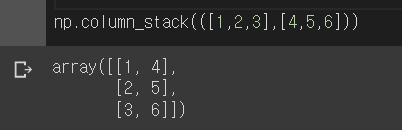
타깃 리스트를 np.ones() 함수와 np.zeros() 함수를 np.concatenate() 함수로 연결해 배열을 튜플로 넘기기까지 한다.
fish_target = np.concatenate((np.ones(35), np.zeros(14)))그리고 심지어 train_test_split() 함수를 이용해 비율에 맞게 섞어서 각 세트로 나누기까지 한다.
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify=fish_target, random_state=42)평균과 표준편차를 훈련 세트의 각 열별로 구하고
mean = np.mean(train_input, axis=0)
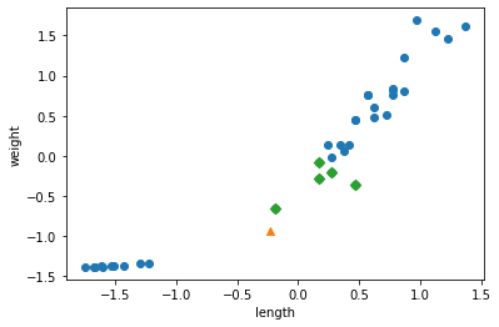
std = np.std(train_input, axis=0)넘파이의 브로드캐스팅 기능으로 각 데이터의 스케일을 맞춰서 훈련시키고 평가한 후 예측하면
다음과 같이 산점도에 맞춰 샘플 [25, 150]가 멀리 있는 빙어가 아닌 도미를 찾아가게 된다.
1주차 진도는 여기까지이다.
다음 단원은 회귀 알고리즘과 모델 규제이다.
아마 추세를 따라 예측하고, 모델의 정확도를 규제하는 내용이 나올 것 같은데
점점 내용이 심화되고 각 상황에 맞는 대표적 알고리즘이 소개되니까
흥미롭고 재밌다.

'Programming > 혼공머신 8기.py' 카테고리의 다른 글
| 혼자 공부하는 머신러닝 + 딥러닝 [6주차]_fin (0) | 2022.08.15 |
|---|---|
| 혼자 공부하는 머신러닝 + 딥러닝 [5주차] (0) | 2022.08.10 |
| 혼자 공부하는 머신러닝 + 딥러닝 [4주차] (0) | 2022.07.27 |
| 혼자 공부하는 머신러닝 + 딥러닝 [3주차] (0) | 2022.07.18 |
| 혼자 공부하는 머신러닝 + 딥러닝 [2주차] (0) | 2022.07.13 |