09-1 순차 데이터와 순환 신경망
이전에 이미지 데이터에 대해 최적화된 신경망을 다뤘다면
이번에는 텍스트 데이터에 최적화된 신경망이다.
텍스트 데이터의 경우 우리가 늘 써봐서 알 듯
굉장히 많은 의미를 함축해서 말할 수 있다.
또한, 속담도 있듯 말은 끝까지 들어봐야 한다.
즉, 텍스트는 시계열 데이터와 같이 순서에 의미가 있는 순차 데이터이다.
텍스트를 단어별로 리스트에 넣어도
단어의 순서를 마구 섞어서 주입하면 안 된다.
여기서는 간단히 긍정과 부정을 나누는 모델을 만들 것이다.
따라서 순차 데이터는 이전에 입력한 데이터를 기억하는 기능이 필요하다.
그래서 출력을 다시 입력으로 사용하는 순환 신경망(RNN)을 이용한다.
참고로 데이터의 흐름이 앞으로만 전달되는 신경망을 피드포워드 신경망이라고 한다.
(합성곱 신경망, 완전 연결 신경망 등등)
물론 새로운 출력이 이전의 출력에 영향을 받겠지만
마치 사람의 기억이 그렇듯 데이터를 입력할수록
최근 들어온 데이터에 비해 오래전에 들어온 데이터의 영향은 적을 것이다.
이렇게 샘플(문장 혹은 문단)을 처리하는 한 단계를 타임스텝이라고 말한다.
즉, 순환 신경망은 이전 타임스텝의 샘플을 기억하지만
타임스텝이 오래될수록 순환되는 정보는 희미해진다.
다음은 순환 신경망 층(셀)의 구조이다.
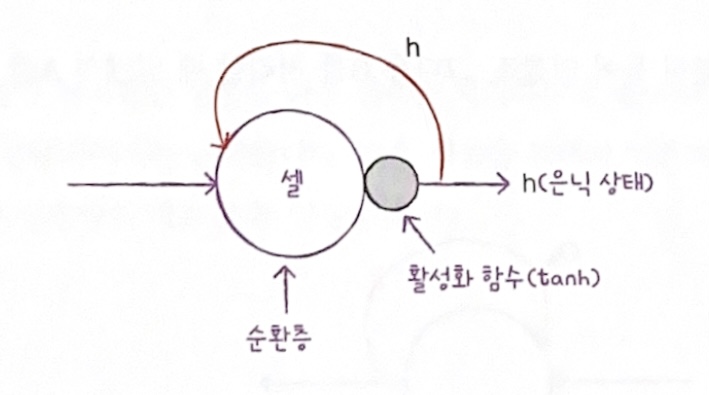
하나의 셀에는 여러 개의 뉴런이 있지만 모두 표시하지 않고 하나의 셀로 층을 표현한다.
셀의 출력을 은닉 상태라고 부르며 다음 입력과 함께 개별적인 가중치를 곱한다.
은닉 상태의 가중치 wh는 타임스텝에 따라 변화되는 뉴런의 출력을 학습한다.
참고로 입력에 대해서는 가중치 wx가 따로 있다.
일반적으로 은닉층의 활성화 함수로 탄젠트 함수를 y=x 대칭시킨
하이퍼볼릭 탄젠트(tanh)를 많이 사용한다.
시그모이드 함수와 닮았지만
변곡점이 원점을 통과하며 -1~1 사이의 범위를 가진다.
셀이 모이면 순환층을 만든다.
이 순환층은 서로의 은닉상태가 공유되어 다음 타임스텝의 뉴런에 완전히 연결된다.
따라서 셀이 n개라면 은닉 상태를 위한 가중치의 수는 n2이 된다.
셀의 최종 출력은 마지막 타임스텝의 은닉 상태이다.
마치 입력된 시퀀스(샘플) 길이를 모두 읽어서 정보를 마지막 은닉 상태에 압축하여 전달하는 느낌
만약 순환층을 여러 개 쌓는다면 이후의 순환층을 위해
이전의 셀은 모든 타임스텝의 은닉 상태를 출력해야 한다.
이렇게 순환층을 거친 데이터는 1차원 형태로 출력되기에 그대로 밀집층에 들어가 마저 가공된다.
09-2 순환 신경망으로 IMDB 리뷰 분류하기
IMDB 리뷰 데이터셋은 대표적인 순환 신경망 문제이다.
유명한 인터넷 영화 데이터베이스인 imdb.com에서 수집한 리뷰를
긍정과 부정으로 분류해 놓은 데이터셋이다.
컴퓨터를 사용해 인간의 언어를 처리하는 (음성 인식, 기계 번역, 감정 분석 등) 분야를 통틀어
자연어 처리(NLP)라고 부른다.
사실 텍스트 자체를 신경망에 전달하지 않는다.
각 단어마다 고유한 정수를 부여해 토큰으로 만든다.
일반적으로 영어 문장은 모두 소문자로 바꾸고 구둣점을 삭제한 다음 공백을 기준으로 분리한다.
한글은 조사가 있기에 형태소 분석을 통해 만든다.
하나의 샘플은 여러 개의 토큰으로 이루어져 있고
1개의 토큰이 하나의 타임스텝에 해당한다.
토큰에 할당하는 정수 중 몇 개는 특정한 용도로 예약되어 있는 경우가 있다.
예를 들어 샘플의 길이를 맞추기 위해 특정 숫차를 채우거나
어떤 숫자는 문장의 시작을 알리고,
어떤 숫자는 어휘 사전에 없는 새로운 토큰임을 나타낸다.
훈련 세트에서 고유한 단어를 뽑아 만든 목록을 어휘 사전이라고 한다.
텐서플로의 IMDB 리뷰 데이터는 이미 정수로 변환되어 있다.
따라서 데이터를 불러올 때 바로 어휘 사전의 단어 수만 지정해주면 된다.
리뷰는 사람마다 길게 쓸 수도 있고 짧게 쓸 수도 있다.
따라서 토큰의 개수를 어느정도 지정해줄 필요가 있다.
짧다면 패딩을 통해 길이를 맞출 것이고
길다면 앞부분이나 뒷부분이 잘릴 것이다.
일반적으로 시퀀스의 뒷부분의 정보가 더 유용하리라 기대되기에 앞부분을 자른다.
또, 긍정/부정의 이진 분류이므로
마지막 출력층은 1개의 뉴런을 가지고 시그모이드 활성화 함수를 사용해야 한다.
이전의 순환층은 하이퍼볼릭 탄젠트 함수를 활성화 함수로 사용한다.
하지만 이대로 진행하면 문제가 생긴다.
토큰의 정수가 클수록 큰 활성화 출력을 만들게 된다.
하지만 우리는 정수의 크기에 의미를 부여하지 않았다.
이를 해결하기 위한 방법이 2가지 있다.
먼저 7장에서 잠깐 보았던 원-핫 인코딩을 통해
정숫값에 있는 크기 속성을 없애고 각 정수를 고유하게 표현할 수 있다.
이 방법은 토큰의 크기를 늘리는 대신 하나만 1이고 나머지는 0으로 만들어 크기 속성을 없앤다.
따라서 입력 데이터가 엄청 커진다는 단점이 있다.
다른 방법으로 단어 임베딩이 있다.
단어 임베딩은 각 단어를 고정된 크기의 실수 벡터로 바꿔준다.
이렇게 만들어진 벡터는 원-핫 인코딩된 벡터보다 훨씬 의미 있는 값으로 채워져 있기 때문에
자연어 처리에서 더 좋은 성능을 내는 경우가 많다.
물론 처음에는 모든 벡터가 랜덤하게 초기화되지만
훈련을 통해 데이터에서 좋은 단어 임베딩을 학습한다.
또, 원-핫 인코딩에 비해 훨씬 작은 크기로도 단어를 잘 표현할 수 있다.
09-3 LSTM과 GRU 셀
기본 순환층은 긴 시퀀스를 학습하기 어렵다.
시퀀스가 길수록 순환되는 은닉 상태에 담긴 정보가 점차 희석되기 때문이다.
따라서 멀리 떨어져 있는 단어 정보를 인식하는 데 어려울 수 있다.
이를 위해 LSTM과 GRU 셀이 발명되었다.
LSTM은 Long Short-Term Memory의 약자로
단기 기억을 오래 기억하기 위해 고안되었다.
LSTM은 순환되는 상태가 2개이다.
은닉 상태와 셀 상태
셀 상태는 다음 층으로 전달되지 않고 LSTM 셀에서 순환만 되는 값이다.
큰 흐름은 다음과 같다.
입력과 은닉 상태는 가중치 w0(wx와 wh)에 곱하고 시그모이드 함수를 통과한다.
그 후 tanh 함수를 통과한 셀 상태를 만나
새로운 은닉 상태를 만드는 데 기여한다.
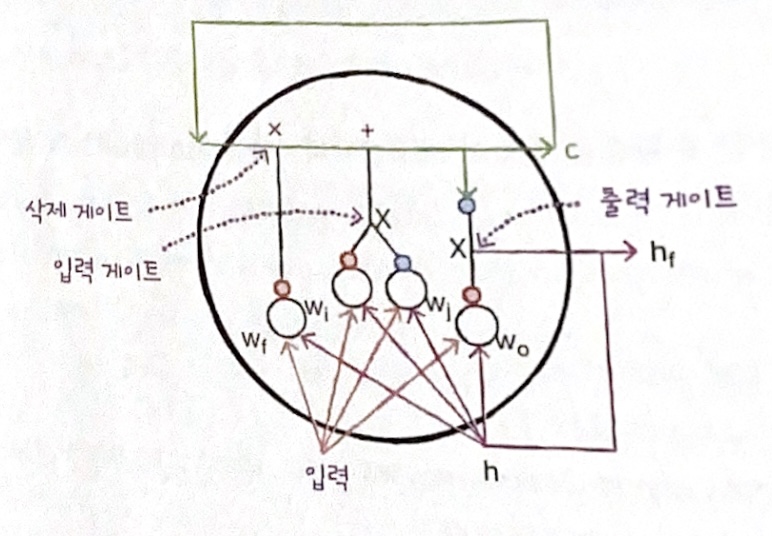
셀 상태의 절차는 다음과 같다.
우선 입력과 은닉 상태를 가중치 wf에 곱한 다음 시그모이드 함수를 통과시킨다.
그 다음 이전 타임스텝의 셀 상태와 곱한다.
이후 다음 과정을 거친 데이터를 더하면 이번 타임스텝의 셀 상태가 된다.
입력과 은닉 상태를 각기 다른 가중치에 곱한 다음,
하나는 시그모이드 함수를 통과시키고
다른 하나는 tanh 함수를 통과시킨 후 서로 곱한다.
LSTM 구조의 세 군데의 곱셈을 게이트라고 부른다.
삭제 게이트는 셀 상태에 있는 정보를 제거하는 역할을 하고
입력게이트는 새로운 정보를 셀 상태에 추가한다.
출력 게이트를 통해서 이 셀 상태가 다음 은닉 상태로 출력된다.
GRU는 Grated Recurrent Unit의 약자로
뉴욕 대학교 조경형 교수가 발명한 셀이라고 한다.
LSTM을 간소화한 버전으로 생각할 수 있고 LSTM과 달리 셀 상태는 없다.
다음은 GRU의 구조이다.
GRU 셀에는 은닉 상태와 입력에 가중치를 곱하고 절편을 더하는 작은 셀이 3개 있다.
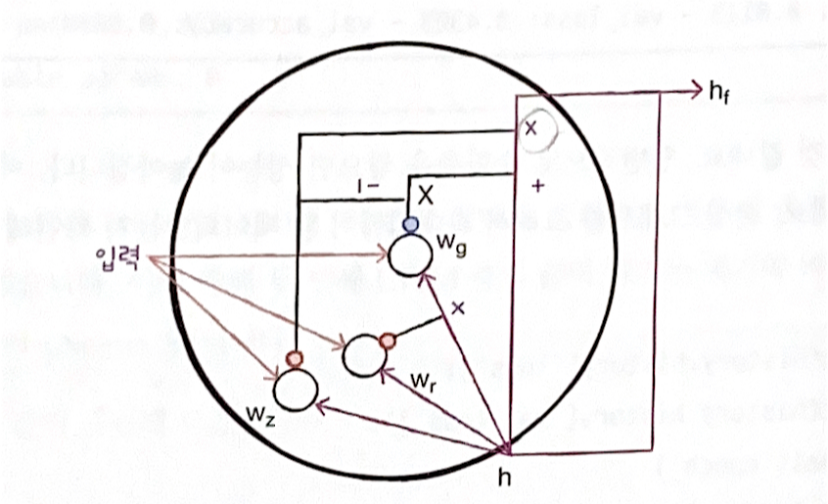
wz를 사용하는 셀의 출력이 은닉 상태에 바로 곱해져 삭제 게이트 역할을 수행한다.
똑같은 출력을 1에서 뺀 다음 wg(wx와 wh)를 사용하는 셀 출력에 곱해
입력되는 정보를 제어하는 역할을 수행한다.
wr을 사용하는 셀에서 출력된 값은 wg 셀이 사용할 은닉 상태의 정보를 제어한다.
GRU 셀은 LSTM보다 가중치가 적기 때문에 계산량이 적지만
LSTM 못지 않은 좋은 성능을 낸다.
'Programming > 혼공머신 8기.py' 카테고리의 다른 글
| 추가 학습(1)_합성곱 신경망 (0) | 2022.08.16 |
|---|---|
| 혼자 공부하는 머신러닝 + 딥러닝 [6주차]_fin (0) | 2022.08.15 |
| 혼자 공부하는 머신러닝 + 딥러닝 [5주차] (0) | 2022.08.10 |
| 혼자 공부하는 머신러닝 + 딥러닝 [4주차] (0) | 2022.07.27 |
| 혼자 공부하는 머신러닝 + 딥러닝 [3주차] (0) | 2022.07.18 |